在全球化和信息技术高速发展的今天,文字编码的标准化和兼容性变得尤为重要。尤其是在中文信息的处理与传输中,乱码问题屡见不鲜。乱码,表面上看似简单的字符显示异常,实质上反映出编码体系的不一致和差异。本文将围绕“解读中文乱码背后的一线二线三线编码差异”展开,探讨不同编码体系在处理中文字符时的差异与影响,以及背后所隐藏的技术与标准问题。
中文字符的编码起源可以追溯到20世纪60年代左右,随着计算机技术的发展,亟需为汉字这样庞大繁复的字符集设计合适的编码体系。最早的编码体系之一是ASCII,虽然在国际范围内广泛应用,但它仅能表示128个字符,远无法满足中文字符丰富的需求。于是,后续出现了一系列扩展和替代的编码标准,其中最具代表性的是GB2312、GBK、GB18030、Unicode等,它们在中国甚至全球范围内都具有重要影响。
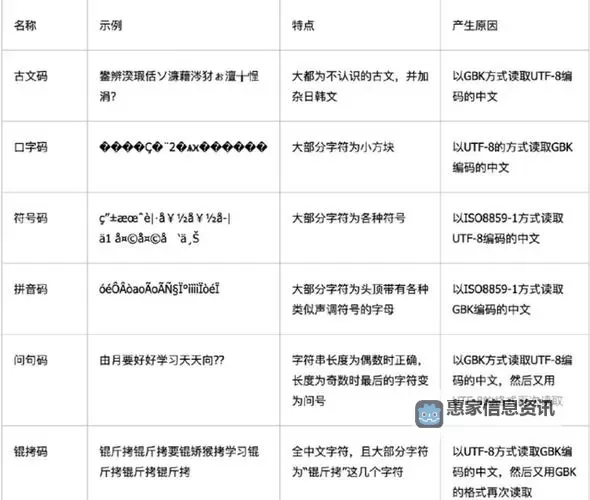
在这些编码体系中,中文字符的编码差异主要表现为“编码层级”或“线”,可以比作编码的“等级”或“层级”。传统上,我们可以将编码划分为一线、二线和三线三个层次,以帮助理解其差异。
首先,一线编码主要指最基础、最早的汉字编码标准,如GB2312。GB2312于1980年代推出,旨在覆盖常用的简体汉字,共收录6,763个字符,采用双字节编码。该标准的最大优势是简洁高效,便于在早期计算机系统中应用,但其字符集较为有限,覆盖面不足,无法满足日益增长的中文数字化需求。编码上的限制逐渐成为局限性,逐步被更新的标准所取代。
二线编码则代表着更为丰富和扩展的编码体系,如GBK。GBK在2000年左右推出,兼容GB2312的字符集基础上,扩充到了1万多汉字,涵盖了繁体字、日文汉字和其他字符。编码方式保持双字节,兼顾旧系统和新系统的兼容,为中文信息处理提供了更大的弹性。它大大提升了字符集的覆盖能力,是很多中文操作系统和应用软件的核心编码标准。二线编码的突出特点是兼容性和扩展性,但在海量字符集面前,仍然出现了一些编码不统一和乱码问题,尤其是在不同系统或版本间转换时。
三线编码则代表着更为完善和国际化的编码标准——Unicode。Unicode旨在统一所有文字字符的编码体系,包括汉字、拉丁字母、符号等。其最大优势在于全球范围内的兼容性和一致性。Unicode采用多种编码方式,如UTF-8、UTF-16和UTF-32,能够灵活应对不同应用场景。对于中文来说,Unicode不仅包含了繁简汉字,还支持大量少数民族字符和特殊符号,极大拓展了表达的丰富性。
然而,三线标准的普及也带来了一些问题。一方面,Unicode庞大的编码空间导致存储和传输成本上升;另一方面,历史遗留系统中仍存在大量以GBK或其他编码存储的旧数据,导致在转换或显示时出现乱码。这也是“中文乱码”问题的根源之一:编码不统一或转换不当导致原本完好的字符信息被扭曲,表现为乱码的现象。
背后,这些编码差异折射出技术发展进程中的挑战。早期的编码标准如GB2312一线编码,追求简洁高效,付出了字符集有限的代价。随着需求增长,二线编码如GBK进一步扩展,但仍然存在兼容性和标准化难题。而进入21世纪,Unicode作为全球统一的编码体系,尝试解决各种字符集的割裂状态,实现无缝的文字交流,但实际应用中仍存在字符编码转换和乱码的问题,这些都源自不同编码层级之间的差异和协调不足。
总结来说,中文编码的差异可以看作是“层级”的变化,从一线到三线,逐渐由有限到丰富,再到统一。每一层背后都代表着不同的技术背景和标准制定思路。理解这些差异,有助于我们在数据交换、系统开发和信息传输中,更好地识别和解决乱码问题,确保中文信息的完整、准确传达。在未来,随着全球数字化进程的推进,推动编码标准的进一步统一和优化,将成为避免乱码、实现无障碍信息交流的重要方向。
Copyright © 2025 惠家信息资讯
抵制不良游戏,拒绝盗版游戏。 注意自我保护,谨防受骗上当。 适度游戏益脑,沉迷游戏伤身。 合理安排时间,享受健康生活